
A corrida por produtos com IA não é mais um diferencial — é uma realidade para qualquer startup SaaS que queira se manter competitiva. Mas antes de sair conectando modelos generativos ou classificadores em sua aplicação, é fundamental garantir que a infraestrutura de dados está pronta para suportar isso.
Neste artigo, compartilho uma abordagem pragmática para desenhar uma arquitetura de dados robusta, escalável e economicamente viável em ambientes SaaS com Java, Quarkus e AWS. A ideia é explicar passo a passo, de forma simples, para que mesmo quem nunca mexeu com IA consiga entender.
Nota: Ao longo do artigo menciono “tenant” ou
tenant_id. Isso se refere a empresa ou cliente isolado dentro do seu sistema SaaS. Um sistema multitenant é aquele onde todos os clientes compartilham a mesma aplicação, mas veem apenas seus dados e operações.
1. O que muda quando você incorpora IA a um produto SaaS
Ao adicionar IA ao seu sistema, você não está apenas chamando uma API que responde inteligentemente. Você está dizendo: “Meu sistema vai tomar decisões ou gerar conteúdo com base em dados”.
Isso exige:
- Dados organizados e de qualidade: o modelo precisa saber o contexto.
- Histórico: para comparar resultados, corrigir erros e reusar entradas.
- Velocidade: quanto mais rápido você processa e responde, melhor a experiência.
Exemplo: imagine um SaaS de atendimento que usa IA para sugerir respostas automáticas. Para isso funcionar, você precisa de:
- Histórico de conversas
- Perfil do cliente
- Tipo de pergunta
- Hora da interação
Esses dados precisam estar acessíveis e organizados.
2. Arquitetura de Referência para Produtos com IA
Aqui está uma arquitetura simples, que você pode usar como base:
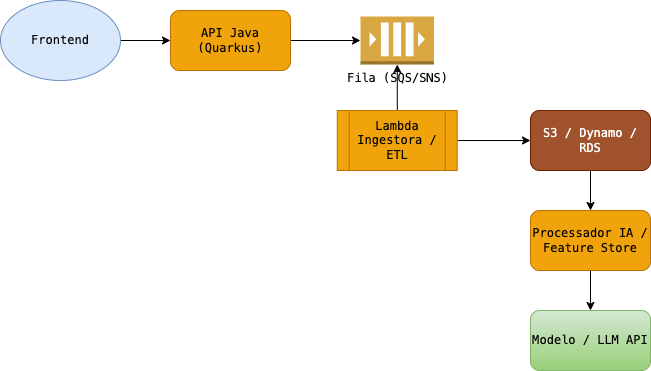
Explicação passo a passo:
- O frontend (React, Angular, etc.) envia dados para sua API (feita em Java, usando Quarkus).
- A API não processa tudo direto. Ela joga um evento em uma fila (como SQS), dizendo: “Novo dado chegou”.
- Uma função Lambda consome esse evento e armazena os dados no lugar correto (S3, banco relacional, etc.).
- Quando esses dados estão prontos, outro serviço pode usá-los para alimentar um modelo de IA ou fazer uma chamada para uma API como a da OpenAI.
Essa abordagem desacopla tudo: você pode escalar, monitorar e testar cada pedaço.
3. Como organizar os dados para IA: structured + unstructured
Para treinar ou alimentar um modelo de IA, precisamos de dois tipos de dados:
- Estruturados: são os dados que você já conhece: tabelas de usuários, produtos, eventos. Fáceis de consultar.
- Não estruturados: textos, PDFs, áudios, imagens. Não cabem fácil em tabelas, mas contêm informação valiosa.
Como armazenar bem:
- Use S3 para arquivos (docs, json, imagens)
- Use DynamoDB para eventos e metadados rápidos
- Use PostgreSQL (RDS) para dados relacionais que você precisa cruzar ou fazer queries complexas
Exemplo real:
Imagine que você recebe um PDF com um contrato. Você salva o PDF no S3 e guarda no Dynamo a info: “Contrato da empresa A, data tal, referente a produto X”. Assim, consegue localizar e relacionar com facilidade.
4. Ingestão de dados com SQS + Lambda + S3
O que é isso? Ingestão é o processo de pegar os dados que entram no sistema e levá-los para o lugar certo, de forma segura, rastreável e escalável.
Fluxo prático:
- A API recebe um novo dado (ex: mensagem, documento)
- Em vez de processar tudo na hora, ela envia uma mensagem para o SQS:
nova_interacao { tenant_id, usuario, conteudo } - A Lambda recebe isso, valida o formato e salva no S3 (ou outro destino)
- Se tudo der certo, dispara um segundo evento: “dado pronto para IA”
Vantagem:
- Você pode reprocessar, escalonar por evento, evitar travar a API e ter um histórico auditável.
5. Processamento e inferência com IA
Inferência é o momento onde você usa o modelo de IA para obter uma resposta.
Pode ser:
- Um modelo treinado por você
- Um serviço externo (OpenAI, Claude, Amazon Bedrock, etc.)
Exemplo: você envia: “Qual a melhor condição desse contrato para um cliente de varejo?”
- O sistema junta contexto: tipo do contrato, perfil do cliente, histórico
- Monta um prompt (texto de entrada) e envia para a IA
- A IA responde
- Você armazena essa resposta com todos os metadados para auditar depois
Boas práticas:
- Use DTOs bem definidos:
PerguntaDTO,ContextoDTO,RespostaIA - Versione cada chamada para reproduzir em caso de problema
6. Monitoramento e rastreabilidade
Se você usa IA para tomar decisões ou responder clientes, precisa saber exatamente o que foi enviado, quando, por quem e o que voltou.
Como fazer:
- Salve logs em JSON com todos os campos relevantes (tenant_id, user_id, input, output, modelo, versão, latência, custo)
- Use CloudWatch Logs ou Elasticsearch + Kibana para visualizar
- Crie um endpoint
/auditoria/iapara times internos consultarem chamadas
7. Dicas finais para startups SaaS
- Comece pequeno, mas bem organizado: buckets com pastas por empresa, nome padronizado dos arquivos
- Inclua sempre o tenant_id em tudo (banco, logs, arquivos)
- Automatize: criação de buckets e permissões por empresa, com Terraform ou CloudFormation
- Monitore custo: IA é cara. S3, logs e APIs de IA precisam ser otimizados
- Use circuit breakers e retries: erros são comuns; se proteja com Resilience4j ou mecanismos do AWS SDK
Conclusão
A integração de IA em produtos SaaS exige uma boa base de dados, muito mais do que um modelo bonito. Com uma arquitetura orientada a eventos, armazenamento bem pensado e rastreabilidade de ponta a ponta, sua startup pode crescer de forma confiável e segura.
Se quiser discutir como desenhar isso para o seu produto, me chama por aqui!